REX Computing Raises $1.25M from Founders Fund’s FF Science to Bring Silicon Back to Silicon Valley
SAN FRANCISCO – July 21, 2015 – REX Computing, a San Francisco fabless semiconductor startup developing high performance energy-efficient computer processors, announced today that it has raised $1.25 million in seed funding led by FF Science, a vehicle of Founders Fund that invests in companies pushing the boundaries of difficult scientific and engineering challenges. The new capital will support continued development and deployment of REX’s new, hyper-efficient and general purpose processor aiming to deliver a 10 to 25x increase in energy efficiency compared to the current state-of-the-art.
“It has been decades since the industry that gave Silicon Valley its name - the business of semiconductors and microprocessors - has managed to produce anything beyond incremental innovation, myopically chasing the Moore's law curve.” said Aaron VanDevender, Chief Scientist at Founders Fund. “REX is rethinking the integrated the computing stack---hardware and software---to produce dramatic improvements in energy efficiency. If we want ubiquitous supercomputing, we can't wait for Moore. We need REX.”
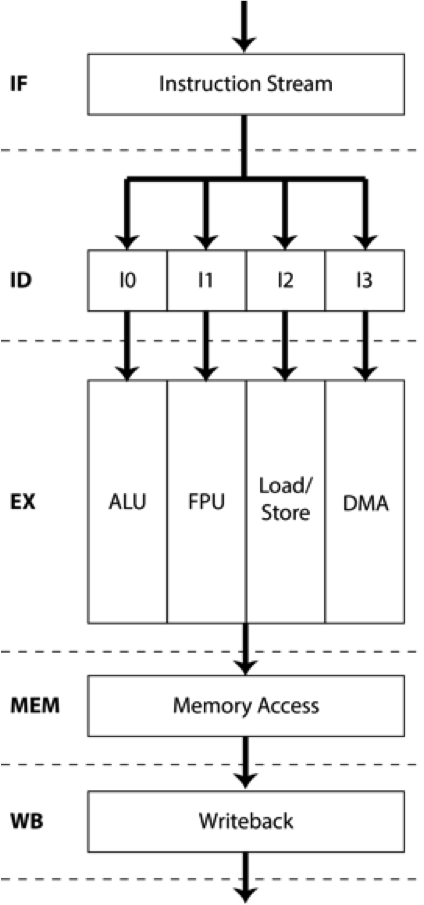
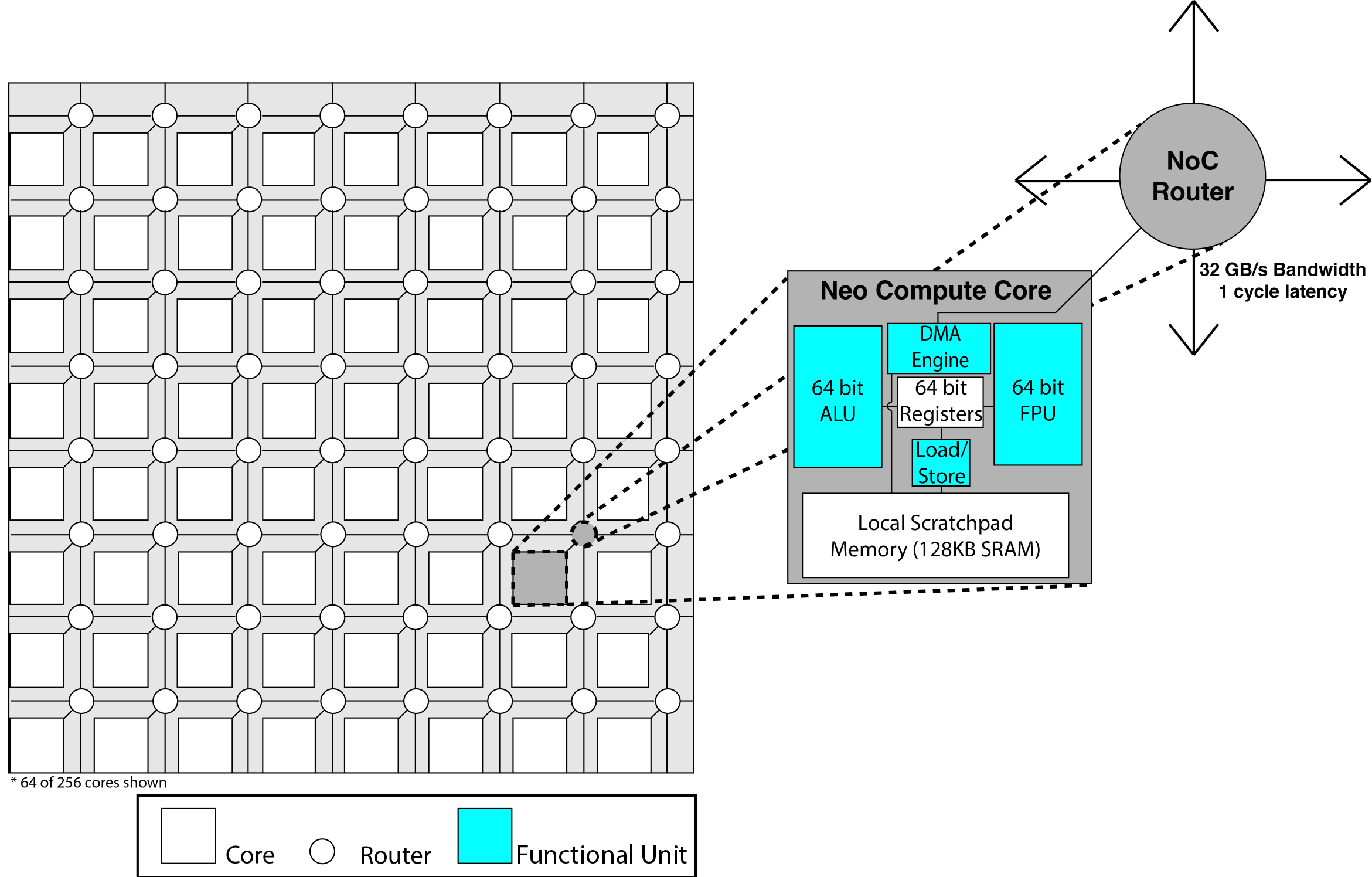
REX Computing was founded in 2013 by Thomas Sohmers and Paul Sebexen following their selection as Thiel Fellows by Silicon Valley investor and philanthropist Peter Thiel. Sohmers started REX to break through barriers in power efficiency and programmability of large-scale computer systems. REX’s Neo architecture is the first solution solving these problems plaguing all areas of computing by targeting the key area contributing to power usage in processors: the memory system. Processors typically require 40 times more energy to exchange data with local memory than performing useful computational work with that data; over 60% of this energy usage is dissipated in the processor’s hardware-managed cache hierarchy. The Neo architecture addresses these problems by removing unnecessary complexity from hardware, resulting in smaller chip area and less power consumption, instead providing similar functionality more efficiently in a rich software toolchain.
“We’ve discovered a major flaw in processor design that has persisted for 20 years. Memory movement is the largest consumer of power and the biggest bottleneck in a modern processor, but the industry has primarily focused on improving raw performance, ignoring the efficiency of data movement.” said Sohmers. “Simply tweaking and patching longstanding chip architectures as industry incumbents have already done will not give us the kind of energy efficiency or performance increases needed to effectively continue Moore’s law. We have rethought computing architecture from the ground up to design our Neo chip, featuring a completely new core design including software managed scratchpad memory, 256 cores per chip, a mesh network-on-chip and a high bandwidth chip-to-chip interconnect.”
The REX Neo processor is targeting 256 GFLOPs of double precision floating point performance with the package and power budget of a smartphone-class processor. The 64 double precision GFLOPs per watt efficiency metric is over 10 times more efficient than the best processors available today. REX is working with early customers in fields related to digital signal processing, image processing, computer vision, machine learning, and other computationally-intensive application spaces, and expects first silicon shipping to customers in 2016.
About REX Computing
Founded in 2013, REX Computing is a fabless semiconductor company developing a new processor architecture solving major problems in power efficiency and programability. The 256-core Neo processor will be the first chip to reach over 50 GFLOPs per watt of double precision processing efficiency, bringing capabilities traditionally restricted to large supercomputers and data centers into low power and embedded application spaces.